DuckDB Analyzer
A powerful tool for analyzing large CSV datasets using DuckDB - a high-performance analytical database system.
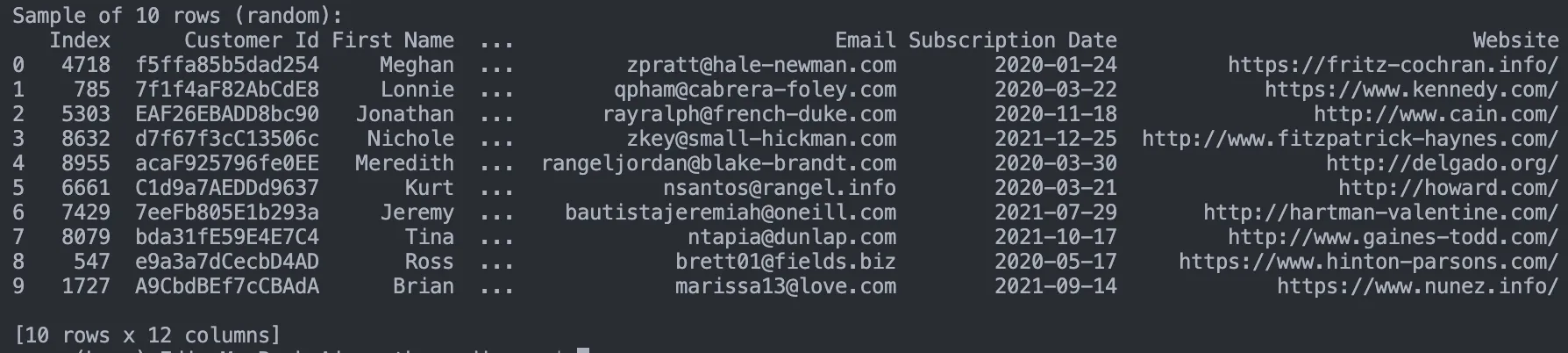
Example - Sample 10 random rows from a CSV file:
🚀 Overview
DuckDB Analyzer simplifies working with large CSV datasets by leveraging the speed and efficiency of DuckDB. It provides a user-friendly CLI and Python API for common data analysis tasks without requiring complex database setup.
Key Features:
- Lightning-fast CSV import and querying
- Memory-efficient processing of large datasets
- Simple command-line interface for common operations
- Python API for integration with existing workflows
- No database server or setup required
📋 Requirements
- Python 3.7+
- Dependencies:
- duckdb
- pandas
🔧 Installation
# Clone the repository
git clone <https://github.com/yourusername/duckdb-analyzer.git>
cd duckdb-analyzer
# Install dependencies
pip install -r requirements.txtAlternatively, create a virtual environment:
python -m venv venv
source venv/bin/activate # On Windows: venv\\Scripts\\activate
pip install -r requirements.txt📊 Usage
Command Line Interface
python duckdb_analyzer.py [options]Get Sample Data
Some great sample data CSV files are available here for free.
Examples:
Count rows in a CSV file:
python duckdb_analyzer.py --file data.csv --action countSample 10 random rows from a CSV file:
python duckdb_analyzer.py --file data.csv --action sample --limit 10 --randomImport a CSV file into a DuckDB table:
python duckdb_analyzer.py --file data.csv --action import --table my_dataGet statistics for a specific column:
python duckdb_analyzer.py --file data.csv --action stats --column agePerform group-by analysis:
python duckdb_analyzer.py --file data.csv --action group --column categoryExecute a custom SQL query:
python duckdb_analyzer.py --action query --sql "SELECT * FROM 'data.csv' WHERE id > 100 LIMIT 5"Python API
from duckdb_analyzer import DuckDBAnalyzer
# Use as a context manager
with DuckDBAnalyzer() as analyzer:
# Count rows in a CSV file
count = analyzer.count_rows("data.csv")
print(f"Found {count:,} rows")
# Sample data
df = analyzer.sample_data("data.csv", rows=5, random=True)
print(df)
# Import into a table
analyzer.import_csv_to_table("data.csv", "my_table")
# Run a custom query
result = analyzer.execute_query("SELECT * FROM my_table WHERE age > 30")🔍 Available Actions
| Action | Description | Required Args | Optional Args |
count | Count rows in a CSV file | --file | - |
sample | Show sample rows from a file | --file | --limit, --random |
import | Import CSV to a DuckDB table | --file, --table | --overwrite |
stats | Get statistics for a column | --file, --column | - |
schema | Show table schema | --table | - |
compression | Show table compression info | --table | - |
group | Perform group-by analysis | --file, --column | - |
query | Run a custom SQL query | --sql | - |
🧪 Performance
DuckDB Analyzer significantly outperforms traditional Python data processing methods for large datasets.
🤝 Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
- Fork the repository
- Create your feature branch (
git checkout -b feature/amazing-feature) - Commit your changes (
git commit -m 'Add some amazing feature') - Push to the branch (
git push origin feature/amazing-feature) - Open a Pull Request
🙏 Acknowledgements
- DuckDB - The analytical database system that powers this tool
- Pandas - For data manipulation and analysis
- DataBlist - For free large sample CSV files for testing.
📜 License
Distributed under the GNU Affero General Public License v3.0 License. See LICENSE for more information.